The following is a full transcript of the presentation The HAM API: 10 Years and Counting given on November 10, 2023 at the 2023 MCN Annual Conference in Philadelphia.
The HAM API at 10
November 14, 2023

Hi. I’m Jeff Steward from Harvard Art Museums (or HAM as I’ll refer to it throughout).
I’m here to tell you about our API.
Rather than show slides today, I invite you to interact with this screen. Just scan the QR and play. Have a bit of fun while I ramble on up here.
If you haven’t experienced our API, I have stickers with the URL. Come get a sticker. Or wait for the slides to go up on Sched.
Our API turned 10 years old in July 2023. 🎂🎉
Hooray for long term projects.
So, I have three stories to tell you about the HAM API in the next 10 or so minutes.
But first a set of acknowledgments.
Acknowledgements
HAM is most definitely not the first museum type institution to have an API. Nor will it be the last. So, I want to start off by acknowledging a few key inspiring and motivating moments that came before us, in the early days of public museum APIs.
Museums and the machine-processable web
http://museum-api.pbworks.com/
This is a cluster of pages in the form of a wiki hosted on PBWorks. This was started and is maintained by Mia Ridge. It is an indispensable accounting APIs for all sorts of cultural institutions and datasets. There is a lot of history to dig into there. The page history for Museum APIs started in 2009. If this stuff interests you, go visit Museum APIs.
Powerhouse Museum APIhttp://api.powerhousemuseum.com/
Now defunct. I first encountered it in 2010. Used it for demos and referred to it endlessly when talking with colleagues about expanded means of access to museums and collections. Thank you.
V&A Collections API
https://developers.vam.ac.uk/
I did an integration for a personal project with it back in 2010 that I used to illustrate to my colleagues the power of interconnectivity. It was a great dataset to have access to for building live, tangible demos. Thank you.
Cooper-Hewitt Collections API
https://collection.cooperhewitt.org/api/
The Cooper-Hewitt API emerged just before ours did in the 2012 or so timeframe. The work they did was a great model for humanizing collections information. And for pushing to publish facets of data like acquisition justifications, and forcing museums to be a bit more public and honest about their reasons for operating the way they do. Thank you.
Brooklyn Museum API
https://www.brooklynmuseum.org/opencollection/api/
For modeling various degrees of transparency around copyright and quality of collections information. Thank you.
Story 1
Stirring the Primordial Soup
2013 was a period of both controlled and unbridled chaos at HAM.
Our hands were in the soup grasping for the building blocks of life. Trying our darndest to give life to a new museum.
HAM was wrapping up a very long building renovation project.
A renovation project that ultimately was physical, virtual, and ideological.
My part in this was to rethink how technology manifests itself to serve the new museum. Then I had to implement parts of it.
In 2012/2013 I was deep in attempting to understand what HAM broadly was trying to become with the building renovation. I did quite a bit of research by visualizing the entirety of the collection. (We have about 250K objects.) This was a bit of a stretch given the data tools we had at the time.
I wrote lots of bespoke queries, with lots or joins with confusing conditional logic, against our TMS and ancillary databases. I extracted large swathes of data to awkward CSV files just to plot a few hundred thousand pixels in Processing. It was onerous. But I got results that sparked a cascade of ideas.

Throughout the process I knew I wanted to do all I could to encourage this same level of experimentation and exploration by students, data minded folks, and those learning the basics of web development.
And to add to the chaos, we were in the process of redesigning our public website and collections search interface with an external firm. This was the third time I worked on a website overhaul with external groups, and explaining the quirks of our collections databases to each of them was tiring. I knew the whole process could be a lot easier.
It was clear we could create an abstract layer to sit between our secure, internal database systems and external users. (This has all been proven repeatedly via the institutions previously acknowledged.)
So we built a built a bunch of PHP scripts to transform and enrich data from our internal system in to plain JSON docs stashed in an external system. Then we built a Node.js application to provide an interface to the JSON docs. This Node API application is the key. It is an implementation of a contract. A contract that defines how you chat with our data. It is the API.
We followed a few guiding principles when designing the application.
1. Provide near real time, instantaneous access to the knowledge produced and managed at HAM.
2. Design a contract that we can commit to and honor, indefinitely. When you create an API, you’re creating a contract between you and the users of it. This is the API at a conceptual level. It’s where you decide on standards and style of communication between the providers of information and consumers of it. Settling the contract is the most challenging part, not the implementation of it.
3. Transcend geography. Provide a platform for anyone around the world with a modest internet connection, and basic knowledge of HTML and JavaScript, to remix and reuse the museums. Let anyone put the museum to use for their own purposes, on their own terms. Full stop.
4. Provide clear, usable technical documentation and provide documentation on how to interpret the data and data structures. We must explain ourselves. (e.g. what is an accession number? Why does the format of the numbers vary so widely? What does classification and work type mean to us? Do we use authorities?)
5. Build the API with enough modularity that we can move parts of it to new services when we need new capacity or need to address issues with cost.
6. Keep the barrier to access and use as low as possible.
7. Offer to do work on behalf of users. Aggregate and rollup statistics. Offer means to compute stats on our end (e.g. see aggregations)
8. Encourage experimentation and imaginative uses of HAM. Make it easy to do research and development, including rapid prototyping with data, at both collections scale and item scale.
9. Think of the API not as a portal to the physicalness of the museum, but as a portal to all the things the museum represents and does. Virtual and physical is contiguous. Honor that.
10. Dispense with siloed data by doing our best to express the fundamental interconnectedness of all things.
So, we coaxed the API into existence over a few weeks in spring 2013 and sent it out into the world that summer.
Story 2
The Common Sense Book of API Care
It takes a bit of money and mental energy to build, run, and care for an API.
The initial development of the code in 2013 was done by me. And the bulk of development, patching, and maintenance is still done by me. (Not that I want to, it a factor of how we’re staffed and organized.) Fortunately care and maintenance is low effort. Most of the work is upgrading the development frameworks as they age out, which occurs every few years. So, there are long stretches of time the code isn’t touched (e.g. Nov 2018 to Jan 2020; March 2021 to March 2022. Zero commits on our Git repository.) If you had a more competent developer, I suspect those stretches could be multiple years.
The application is written in Node. It is built on the Express framework. It runs on Heroku. We’ve been deploying and running our production API on the same Heroku app server since September 2013. We pay $100/month for Standard 2x dynos. We pay $30/month for logging with Papertrail.
The JSON docs are stored in Elasticsearch. We buy the service directly from Elastic. It costs us on average $500/month. (Price fluctuates with workloads.) We used to run Elasticsearch ourselves on hand crafted AWS servers. But time is money, and it wasn’t worth our time to maintain this.
We have a second API for serving IIIF presentation manifests. It has one basic function. It does a near-real time transformation of data from our primary API in to IIIF manifests. In other words, it reshapes our HAM data model into other standards. This application also runs on Heroku for $7/month. We expect this pattern of providing alternate data formats to continue as new data models emerge.
So, the total monthly expense on these pieces is $637. Or $7,644 per year.
Building on this.
As mentioned earlier, we strive to provide near real time, instantaneous access to our knowledge. To that end, our data is a living, breathing entity. What does this mean in practice? It means we publish our entire dataset every single day. If you subscribe to the Gregorian Calendar that’s 365.2425 days a year. (366 during leap year.)
No rest for the wicked and such.
This adds a few more costs for us. All of which are psychic costs.
A 24/7 API. Who’s tending to it? Who’s keeping an eye on it?
Who keeps an eye on all the dependencies throughout its indefinite life?
How do we deal with those breaking changes?
Does this piece of the museum have a financial impact if it goes down?
How do changes in the underlying source databases impact the behavior and contract of the API?
How do changes in cataloguing practices impact the behavior of and contract of the API?
Big questions to grapple with if you make APIs that are critical to your infrastructure.
The answers will vary from institution to institution.
These are the questions that eat my brain and make wonder if I have any clue about what I’m doing.
Story 3
Life Finds a Way
Lastly, I’m going to talk just a bit about how the API is used.
The API started out as a project to address many of our internal needs, with the full understanding that it would simultaneously be publicly available.
And that is how it played out.
Once you release things into the wild, it’s interesting to just sit back and see what happens to them.
We don’t talk about our API all that much.
I’m not proactive with outreach.
We haven’t forged meaningful relationships with external groups to promote it. Somewhat intentionally, somewhat because of time constraints, and truthfully, because institutional support isn’t there.
With all that said, our API is having a pretty good life.
We have a basic automated key system which helps us gain some insights into where it has gone.
8,004 keys generated in the past ten years [from October 2013 to November 2023].
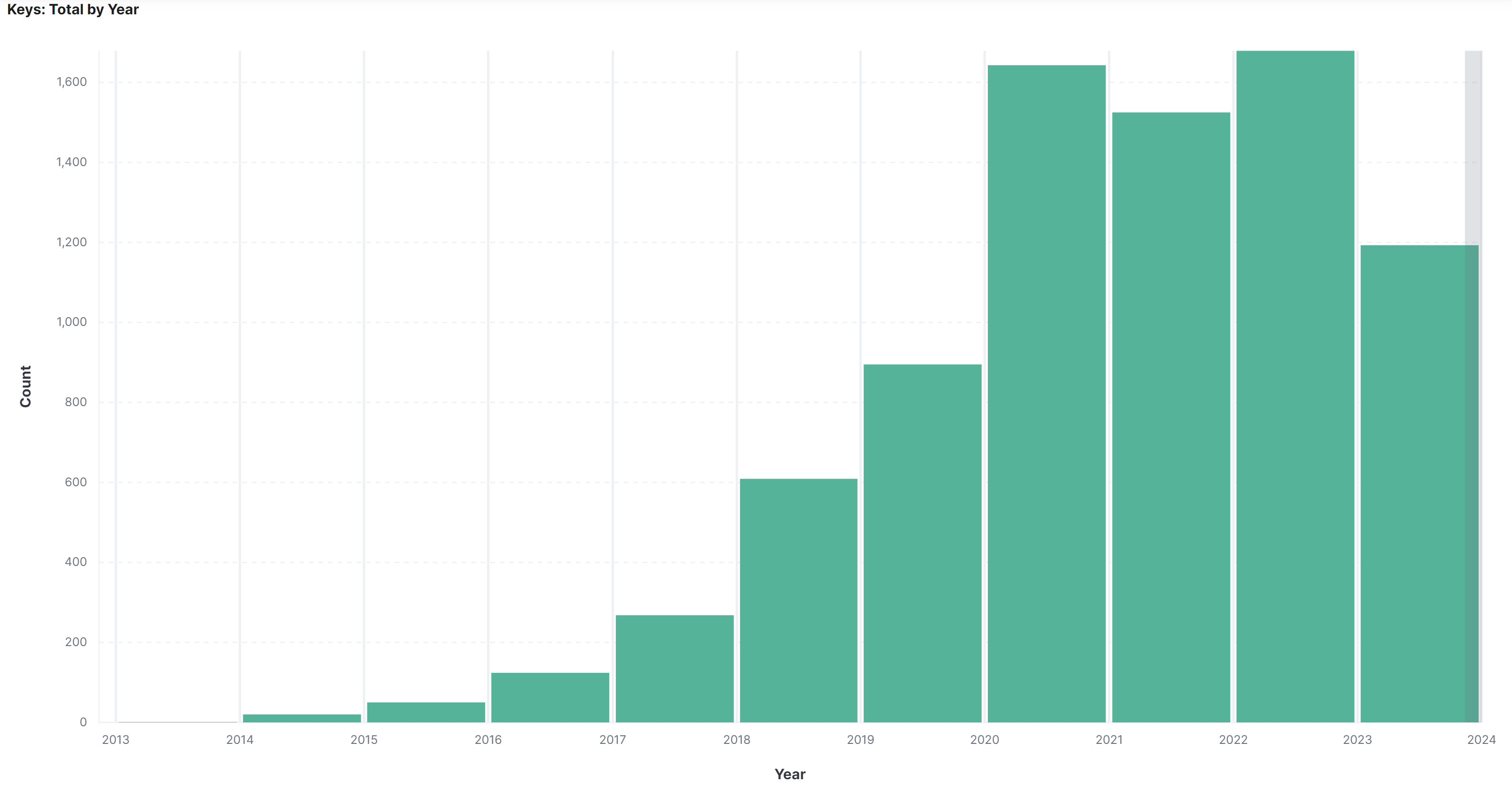

It’s been used for many projects including a string of projects by Harvard metaLAB called Curatorial A(i)gents, and probably the most thorough use of it, an experimental exhibition in July 2022 called Processing the Page: Computer Vision and Otto Piene’s Sketchbooks.
We’ve learned that the API was picked up by other universities before it was picked up for teaching at Harvard.
It’s been used at Yale, MIT, Middlebury, Georgia Tech, The University of Applied Sciences Potsdam, Tilburg University, and about 200 other different institutions with .edu addresses.
Finally in October 2022 it was made a star in the HarvardX course: Digital Humanities in Practice: From Research Questions to Results.
As for the future of the API, we just don’t know.
We’ll nurture and tend to its needs because it is now part of the HAM family.
Thanks for listening.
End of transcript.
Related articles

A Tribute to Those Who Build Our Stuff
How do custom gallery furnishings, such as pedestals and special mounts, make the journey from design to visitor appreciation? Through good craftsmanship.

Giving the Dead Their Due: An Exhibition Re-Examines Funerary Portraits from Roman Egypt
In a powerful exhibition, four ambitious curators tell the most complete account to date of a deeply misunderstood object: the Roman Egyptian funerary portrait.

@busch_hall Conversations: Lynette Roth and Joseph Leo Koerner
The Busch-Reisinger Museum’s new Instagram account @busch_hall hosts conversations with established and emerging scholars, contemporary artists, and museum peers on Instagram Live.