The following is a full transcript of the presentation An AI, a Curator, and an Elephant Walk into a Museum… given on November 17, 2023 at Fantastic Futures (AI for Libraries, Archives, and Museums) in Vancouver, British Columbia, Canada.
AI at HAM: The Early Years
November 25, 2023

Hi. I’m Jeff Steward.
I’m here to tell you about the confluence of AI and Harvard Art Museums (or HAM as I’ll refer to it).
For the next few minutes, I ask that you put yourself in an art museum mindset.
Here is the order of operations.
I’m going to tell you about HAM. Then two whimsical stories. Then some facts. Then we’ll look at a few practical applications. Then I’ll share a few discoveries. And, if time is on my side, I’ll mention some of our future work.
Part 0
About HAM
Harvard Art Museums is a teaching and research museum on the campus of Harvard University in Cambridge, Massachusetts.
We have a collection of 250,000 art objects. A world renown collection of historical pigments. Collections of artists materials and artist archives. And a significant archival collection containing the history of some of the first museum training programs that put museums on the path to professionalization as we know it today.
Part 1, Story 1
Chasing Elephants
A moment of whimsy.
I like to take meandering strolls through our collections. During these moments I do my best to set my mind free and look at art anew.
About 12 years ago, while on a stroll, I stumbled upon an elephant in the museum. At the time I was amused by finding an elephant in one of our rooms, but didn’t think much else about it. I filed this experience away and kept strolling.
As the days and months went on, I took more strolls looking for inspiration in our collections.
On some of these occasions the elephant popped up. Once again, I was amused, then carried on my way. That is, until one day on another stroll, I nearly walked right into the elephant.
I was amused once more, because it seemed like the elephant was starting to toy with me. It’s like it was saying, “Never thought you’d find me here, did you?”
I became pretty convinced it was trying to lure me into a game of hide and seek. So…game on.
We went back and forth for years. Some time it would throw me a bone. Popping up in all its glory.
Other times it would cloak itself. Clever pachyderm!
It would often hide in plain sight. Daring me to find it. Making me pause and wonder if it really is there. And wouldn’t you know it?
Occasionally it would bring friends along. These elephants would jump between artworks with such grace. Traversing the art museum so effortlessly.
So clever with their hiding spots. So playful throughout this game of hide and seek. So clever with how they’re leading me through the collections.
Now when I stroll through the collections, I no longer shy away from the elephants in the room.
I let the elephants be my guide.




Part 1, Story 2
Can we agree to disagree?
One afternoon I was chatting with a few AIs. We were looking at this photograph.
I turned to Clarifai and asked what time of day it thinks the photo was taken. It was like, “I’m 97.2% certain it was taken at dusk.” But then it hesitated and said, “But I’m also 97% sure it was taken at dawn.”
It looked nervously over at Google Vision as asked, “What do you think?”.
Google was like, “It’s most definitely a red sky at morning. I’m a solid 85.2% confident in my opinion.”
“Hey, Imagga, what do you think?”
Imagga, never quite confident in itself, blurted out “sunset” (with 45.9% confidence in its voice). Then seconds later followed up meekly with, but maybe it’s “sunrise” (registering a mere 29.1% in confidence).
Amazon was like, “nope, it’s the moon”.
Clarifai piped back up and said with 87.3% finality, “regardless I declare this to be art.”
Part 1, Story 2, Chapter 2
AI is people
In 2017 we started a project called Project A.L.I.C.E. ALICE is an acronym for Advanced Listening Interface for Curious Earthlings.
The project centered on work a colleague and I did with an undergraduate student with low-vision.
The student wrote a set of guidelines and best practices for visual descriptions based on her specific needs. We put the guidelines in to practice by writing descriptions of several paintings. Then we recorded ourselves reading them for inclusion in an audio guide.
For the project, I wrote a visual description and made a recording for this painting.
I described the painting as depicting sunrise on a calm day.
Days after I wrote that description, one of our curators listened to the recording of it. They said based on research with other colleagues, they believe the painting depicts sunset.
That bit of information, that human interpretation, is nowhere in our catalogue. So, in a flash I felt absolved of my ignorance. And just a bit freer. Freer to embrace the power of interpretation. Free to interpret the painting based on my understanding of the world. Free to participate in the messiness of intelligence and experience. Free to embrace the beautiful, subjectivity of art.
Part 2, Section 1
CV at HAM
At present, when I talk about AI at HAM I’m talking about computer vision (CV). Most of our work to date involves using computers to look at art.
We’ve been doing this in some form since 2013. First, with image recognition tools such as LAYAR. Then on to services such as AutoTag.me (which has gone on to become Imagga).
We began digging into CV in earnest in 2014 for a few simple reasons.
- To expand pathways into the collection.
- To expand our vocabularies and decorate our records with a variety of descriptions.
- In the spirit of research, to gain some insight into how black box CV systems operate.
But, more fundamentally, I just want to know: What do machines see when they look at art?
Part 2, Section 2
Data Pipeline
Let’s look at some of the infrastructure (we use to track elephants).
Here’s a very brief and high-level overview of our core collections-based data pipelines and applications.
Smack in the center is our databot. This is where the magic happens. The databot runs through a series of scripts to enrich and transform our data.
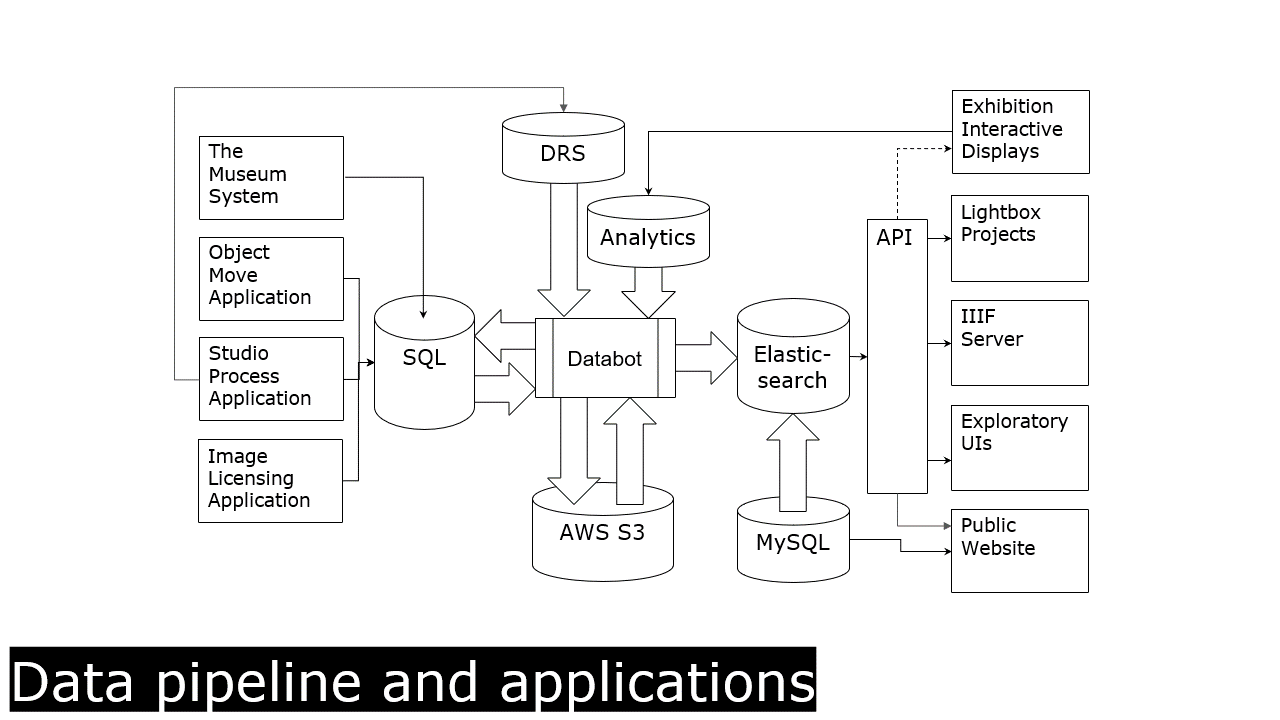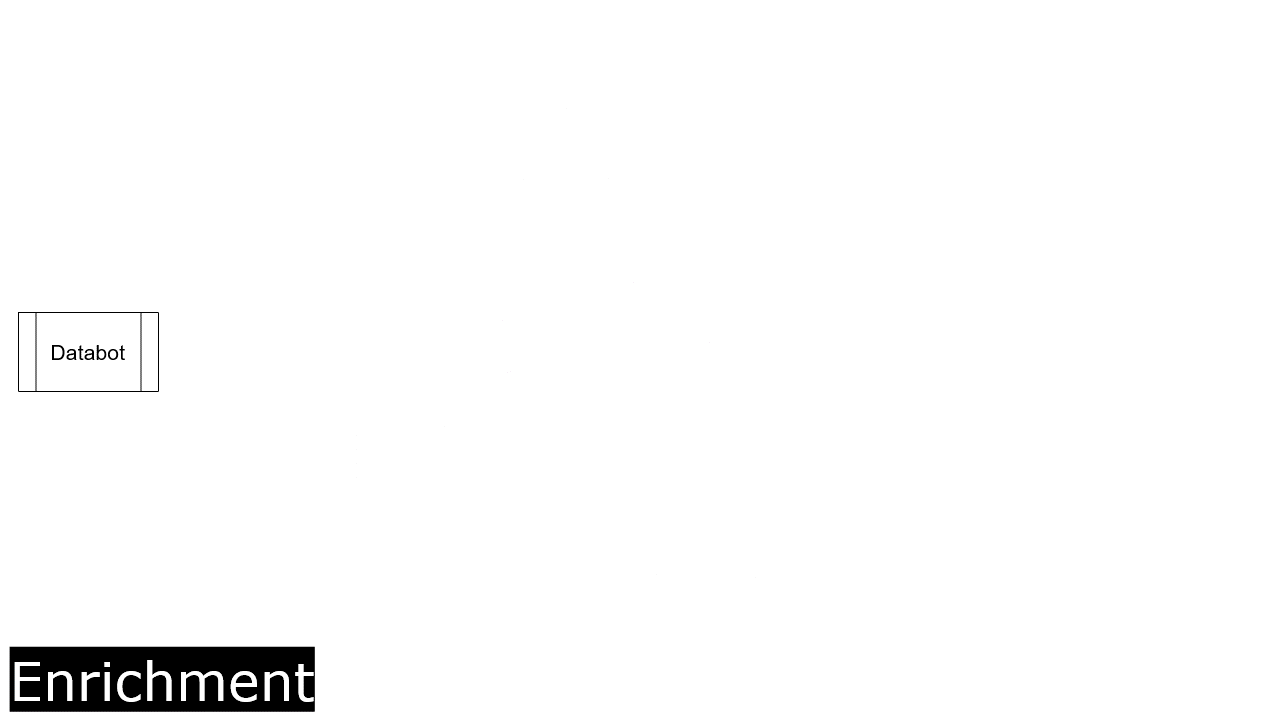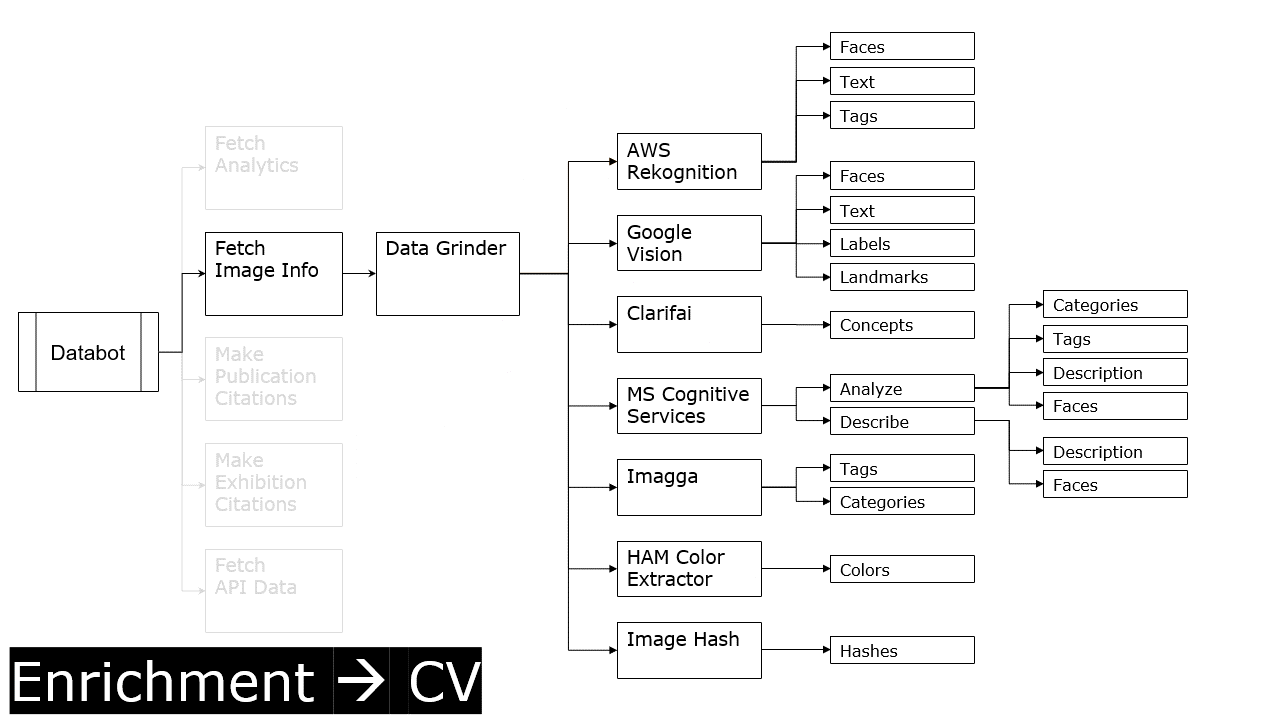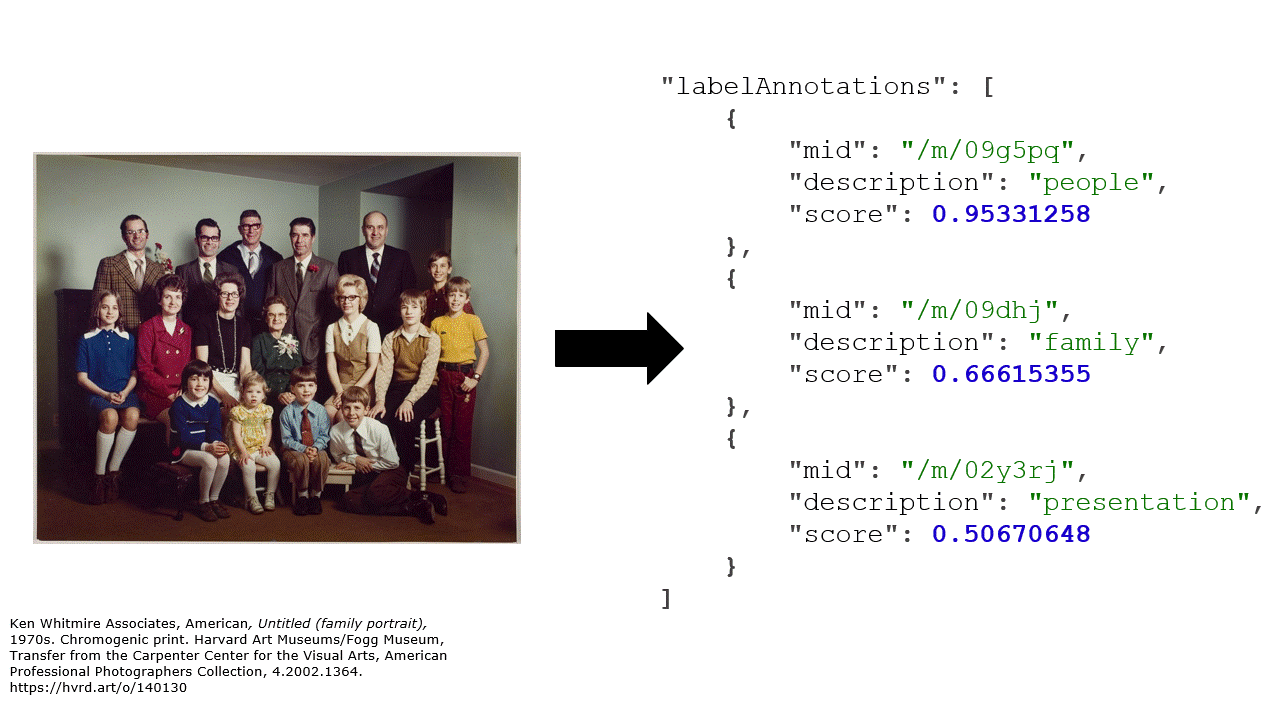
First it [databot] fetches some of our analytics data. Then it goes on to do some image processing. (This is the most relevant step for the topic at hand.)
Peering into the image processing function, shows we’re processing every image in our collection seven different ways. Each image goes through five external CV services, then a series of hashing functions, and finally through a custom color extraction service.
So, image goes in. Tags, categories, features, and descriptions come out. We parse, store them, and ship them back out via our public API.
To date we’ve described 377,000 images, which has generated 53,000,000 annotations. (We classify the output as annotations in our database and data model.)
Part 3
Actual Uses
I’m going to tour through three projects that illustrate how we use the data to promote creative thinking, build large scale interactive data visualizations, and run participatory games.
Use #1
The most practical and direct is our AI Explorer website. It’s a search and browse interface built on the AI generated data. This is most definitely a slow moving, public research project. Be sure to check out the stats page for insights into the vocabularies generated by the services.
Use #2
This [Processing the Page: Computer Vision and Otto Piene’s Sketchbooks] is a project I developed with former curatorial fellow Lauren Hanson from 2019-2022. You’re seeing the project as it was installed in the museum in July 2022. The iPad (or your own phone) was used to control the big screen.

We mined about 10,000 pages from 70 years of sketchbooks by the artist Otto Piene. (This is just a small slice of the images.)

We screened and clustered them by various tagging mechanisms, including the AI generated descriptions.
We used the data to visualize the material in novel ways. Which led us to find repeating themes and motifs. It led us into chasing rainbows.
I have some videos of the UI [Browse Mode and Explore Mode] in these slides. I’m going to skip past them since time is limited today.

Use #3
A(Eye)-Spy is a game to be played with a group of people in the museum galleries.
One person runs the game by broadcasting AI generated tags to the players. The players are to roam the gallery and guess which art object the AI is describing.
The game is a conversation starter. "Why did the AI say that? Why didn’t it say this?" So on and so forth.
Come visit HAM. We’ll play the game together. It'll be fun.
Part 4
Discoveries
So, what are the AIs saying about our collections? Let’s poke these black box systems and get them to open up so we can see the good, the bad, and the horrifying.
Exhibit #1





This is a painting by Sarah Miriam Peale.
Microsoft gives us three pretty straightforward captions. This is ok. I don’t see the cake. Nonetheless it got the gist of the composition. Fruit/food on a table.
Amazon gets the basics.
Google gets better. Still describing literally what we see, but applying more scientific terms. Now classifying the watermelon as citrullus and the image as a painting.
Imagga is more interesting. Not only does it tell you what is depicted but it starts to layer in words that describe what it would be like to experience what you see. What would it be like to eat some of those fruits?
It’s suggesting benefits. It’s describing an experience. It’s not just telling you what to see but what to feel. It’s starting to express opinion and bias.
Clarifai is equally interesting. It’s similar to the other AIs, but takes a turn and chooses to identify what isn’t there. It’s 99% confident there are no people. I can’t argue with that.
Exhibit #2

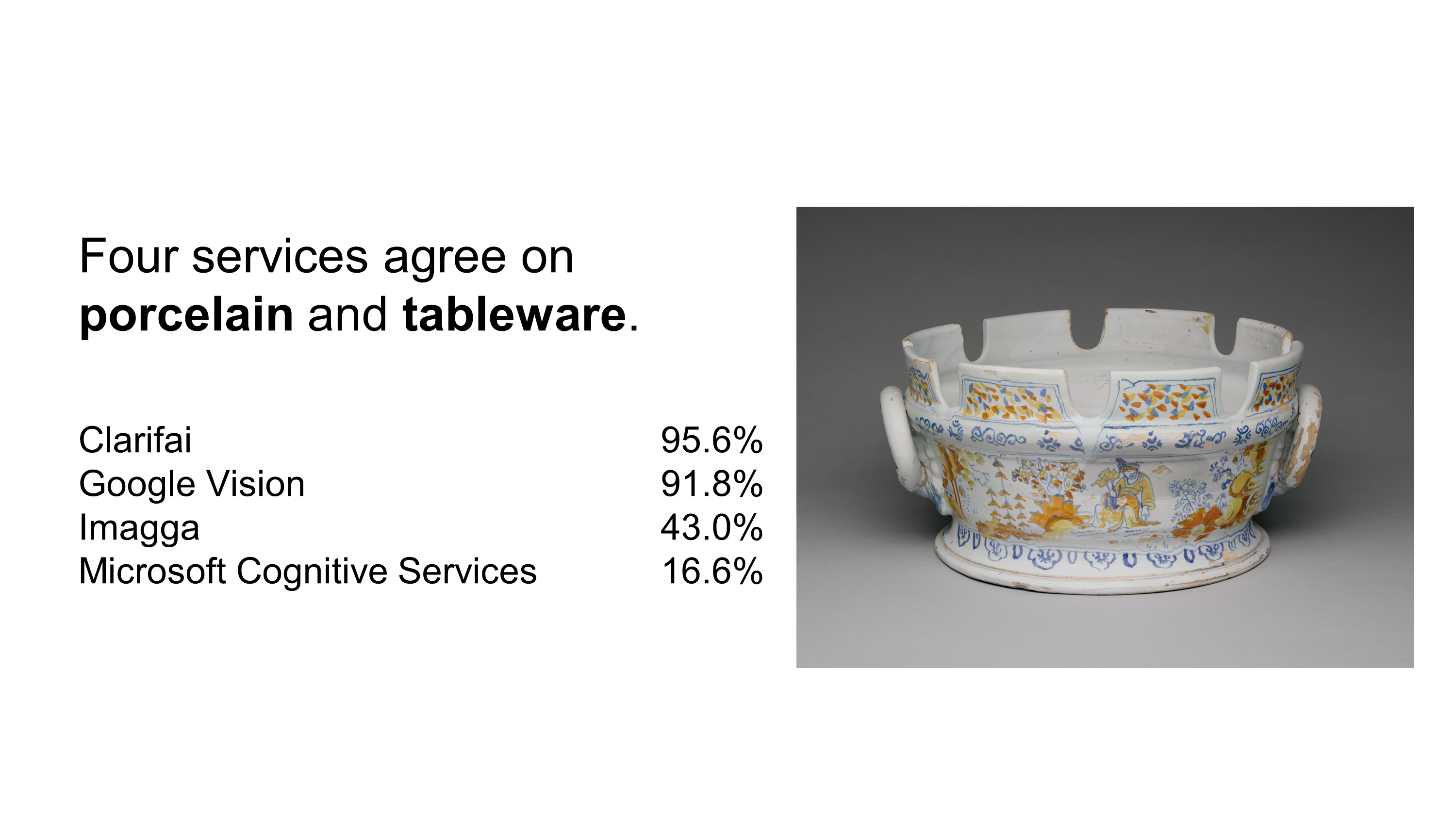





1 of 7
Four services agree this is porcelain and tableware.
Imagga again is talking about purpose and use. And goes on to hint at specific moments you might use it. Perhaps it’s an eight person cereal bowl?
Google goes on about it being a product.
When looking at the data, I always wonder “where did these AIs go to school?”, “what industry do they serve?”
Clarifai stays the course and says no person. Except I have to disagree because there are people on the bowl itself.
Finally Microsoft. Note the difference between the tagging process and description process.
I enjoy this disconnect.
Microsoft sets two different minds on this object. I like to imagine one was trained as a potter. Perhaps the other learned about objects solely by watching baking reality tv shows.
Exhibit #3

This is an engraving from around 1590. I enjoy what the AI services made of this one.
Imagga says it’s a Banknote. I like this.
Google tags it with the phrase, “Small to medium sized cats”.
Then AWS does stellar forensic analysis. It labels the skull. AWS screams, “Your AI future was so yesterday.”
Exhibit #4
[Skipped because of time constraints.]
Exhibit #5
This is a red stone cylinder seal with herringbone pattern from thousands of years ago.
Imagga, AWS Rekognition, and Clarifai all say it is pork. I think we found the new HAM icon. Thank you AIs.
Part 5
Today is the Future
For now I’ll leave you with this: Our plans for the future include guided hallucinations.
Thanks for listening.
End of transcript.
Related articles

A Tribute to Those Who Build Our Stuff
How do custom gallery furnishings, such as pedestals and special mounts, make the journey from design to visitor appreciation? Through good craftsmanship.

Giving the Dead Their Due: An Exhibition Re-Examines Funerary Portraits from Roman Egypt
In a powerful exhibition, four ambitious curators tell the most complete account to date of a deeply misunderstood object: the Roman Egyptian funerary portrait.

@busch_hall Conversations: Lynette Roth and Joseph Leo Koerner
The Busch-Reisinger Museum’s new Instagram account @busch_hall hosts conversations with established and emerging scholars, contemporary artists, and museum peers on Instagram Live.